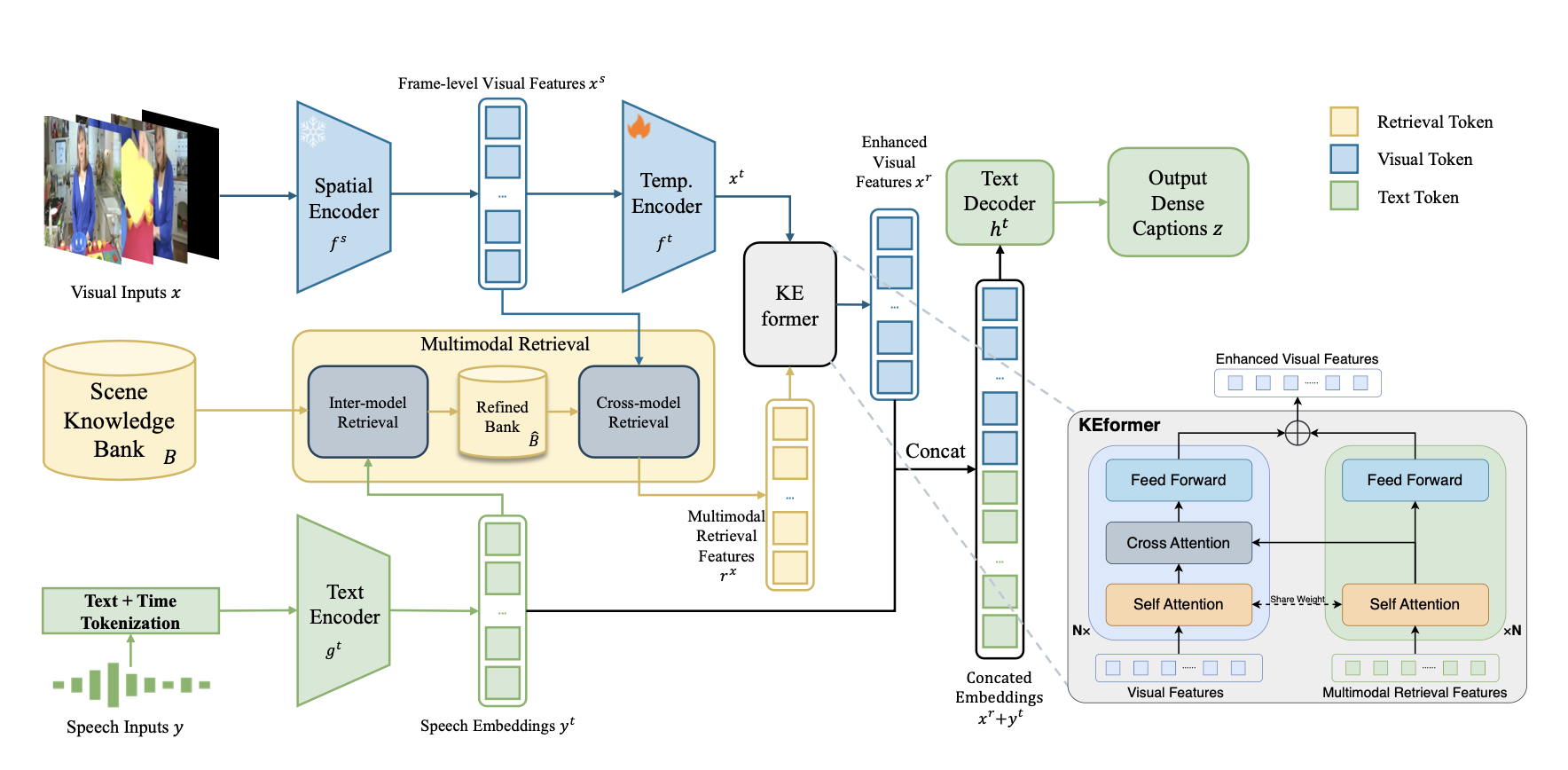
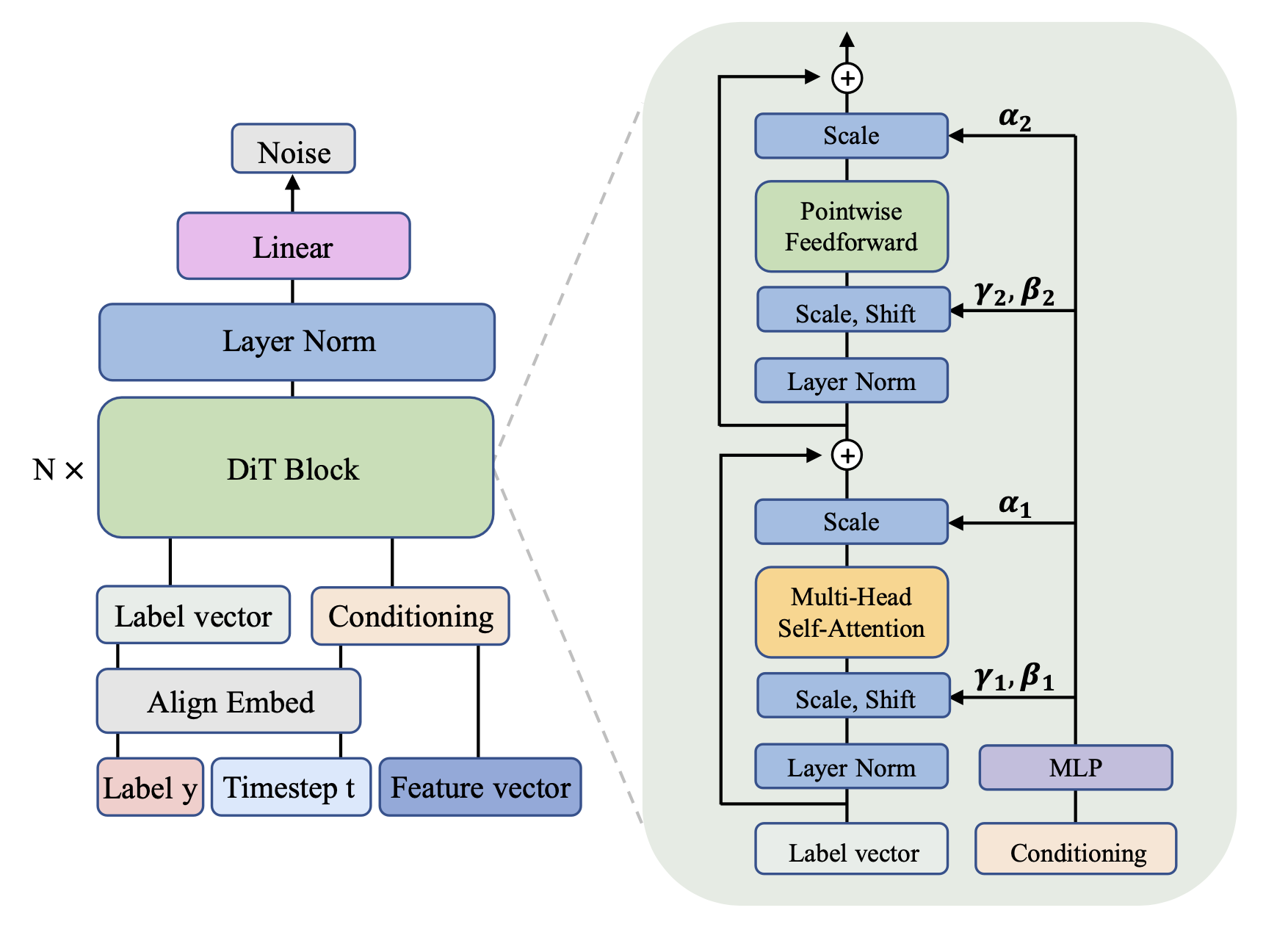
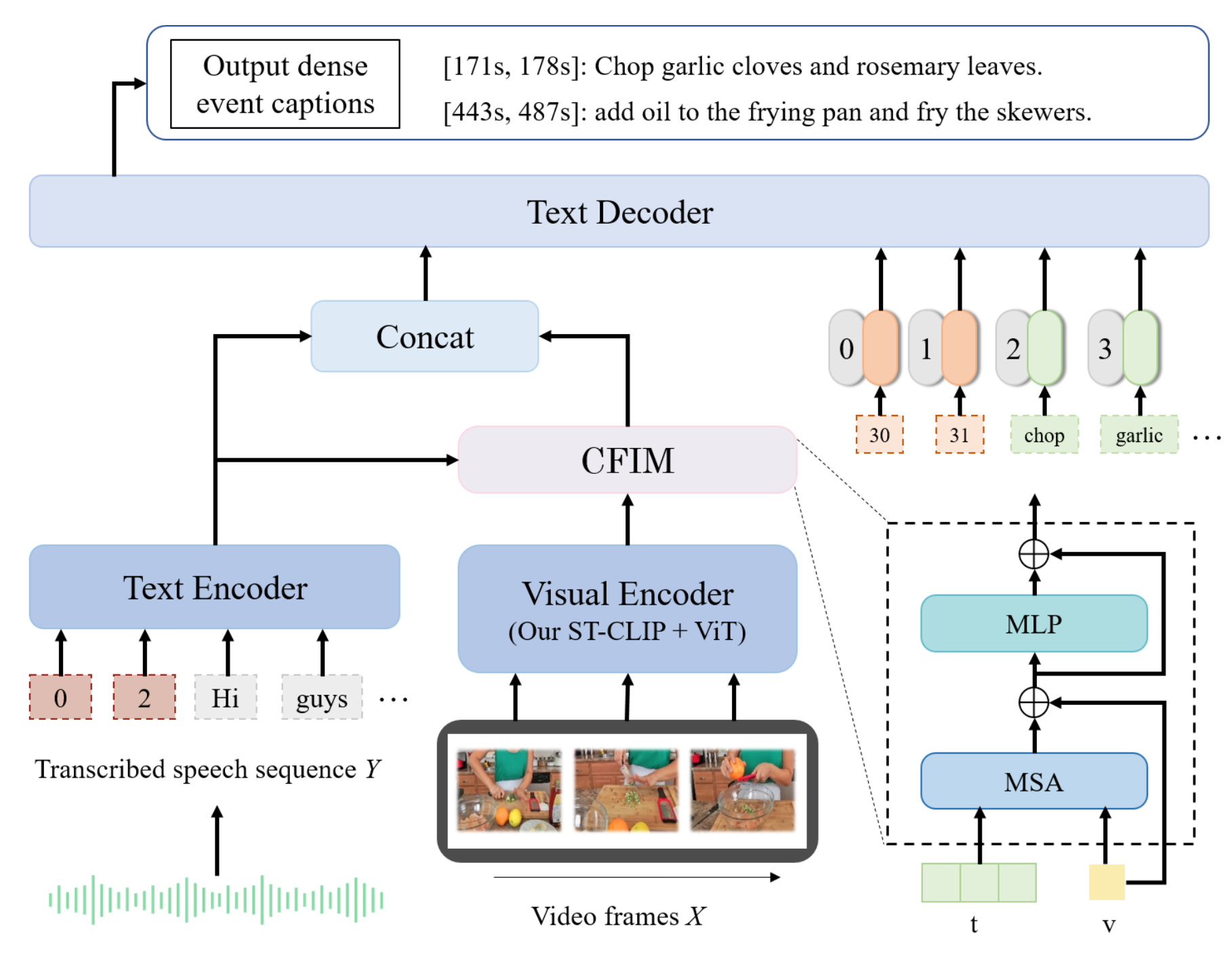
Hello, I'm Mingru Huang
I am a Master's degree student at Wuhan University of Technology. I'm passionate about computer vision research, particularly video understanding. My work spans video Q&A, video-text retrieval, and video captioning. I also explore large language models, prompt engineering, operator development, knowledge graphs, and Q&A systems. My goal is to develop an affordable, secure, and trustworthy generalized multimodal video model for everyone.